
The Company Brain Has Four Stages, Not Two
Why “self-healing AI” is the wrong ceiling, and what I learned this week about building systems that actually improve themselves


Everyone talks about building self-healing, self-learning AI inside their company. After another week deep in our own company brain, I think that framing stops short. There are not two stages. There are four. And the gap between them is where most systems quietly break.
Building AI is also a study in how I learn. The deeper I go into the architecture, the more the architecture turns into a mirror. This piece is what came out of that mirror this week.
The Four Stages of a Self-Improving System
Self-awareness is the foundation. You cannot improve what you cannot see. For an AI system, this means documenting everything. Every action, every output, every state change. Self-knowledge starts as observation, and observation starts as a record.
Self-repair is the deterministic layer. If a switch is supposed to be on and it is off, you turn it back on. No intelligence required, no alarm needed. This is the layer most teams reach for first because it is concrete and bounded.
Self-learning is where intelligence enters. Once you have documented enough repairs, patterns emerge in the documentation itself. The system starts to notice that this tends to happen when that happens. Cause and effect surface from the noise.
Self-evolving is the payoff. After learning the patterns, the system designs new structures and new skills to address them. Not patching the same leak repeatedly, but redesigning the pipe.
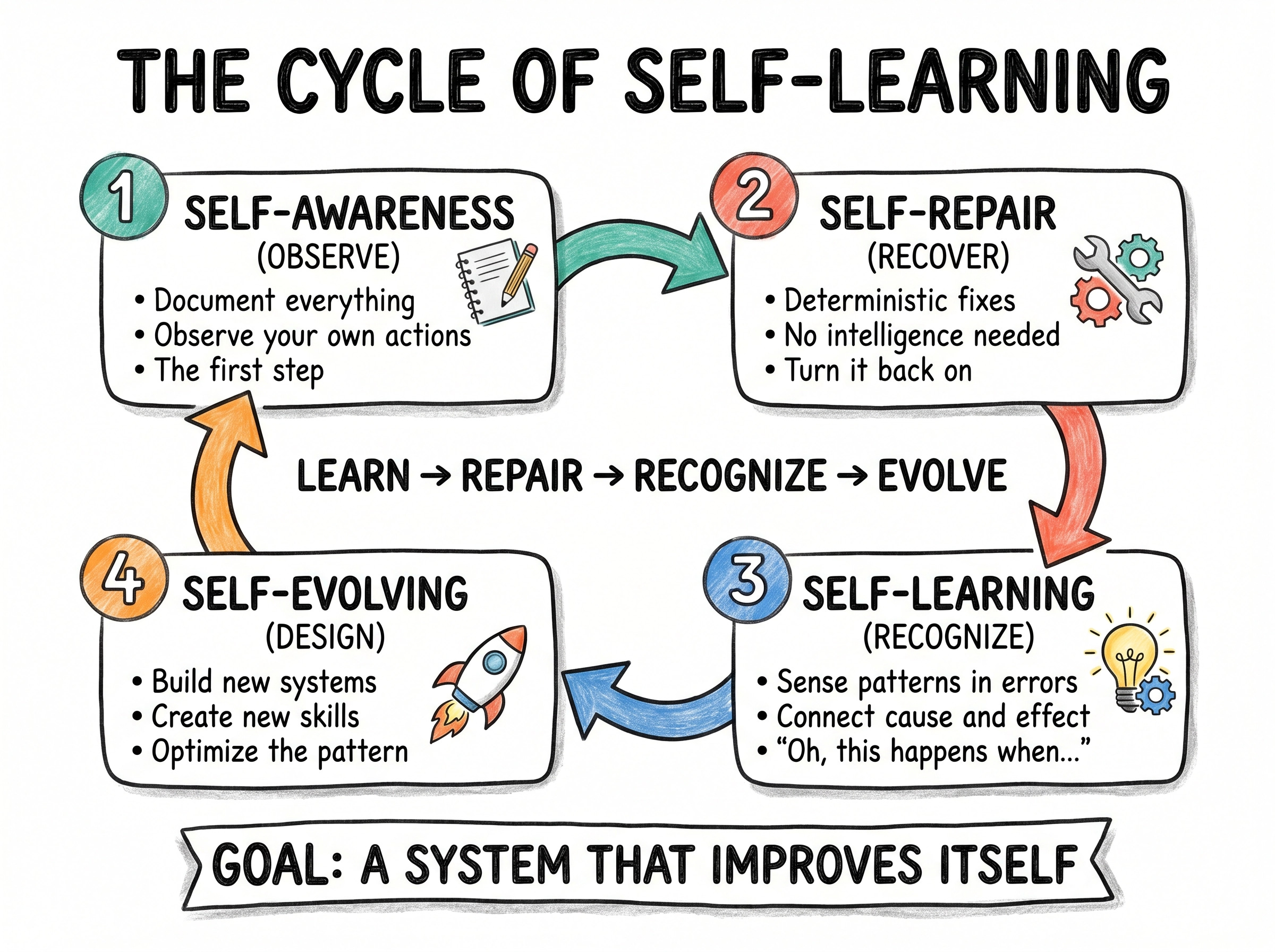
Most teams collapse these four into two and call it self-healing. The collapse is what makes the system fragile.
The Order Matters
I had been wrestling with how to sequence the build when I ran a session with Codex. Surprisingly, not Claude Code, since I had been locked out by Claude Code that day on token credits. Opus 4.7 is a token eater, for what it is worth. Codex articulated the sequencing more cleanly than I had:
“Aim for this order: self-observing, self-recovering, self-repairing, self-evolving. Deterministic watchdogs can restart, catch up, quarantine, and roll back known-safe things. LLM agents can diagnose, classify, draft PRs, and propose policy changes. Humans keep approval over secrets, guardrails, deploy paths, migrations, and any cross-tenant or privacy-sensitive rule changes.” — Codex
The principle underneath is a division of labor between the deterministic and the intelligent. Watchdogs handle the bounded, reversible work. LLMs handle the interpretive work. Humans hold the keys to anything that changes the rules of the game. That ordering is the safest path to a system that mostly runs itself without quietly becoming dangerous.
Every System Needs a Watchdog. Then a Watchdog for the Watchdog.
The second principle I keep returning to is that no critical system should run without independent review. One watchdog is not enough. You want a meta-watchdog watching the watchdog, and any high-stakes decision needs a second pair of eyes.
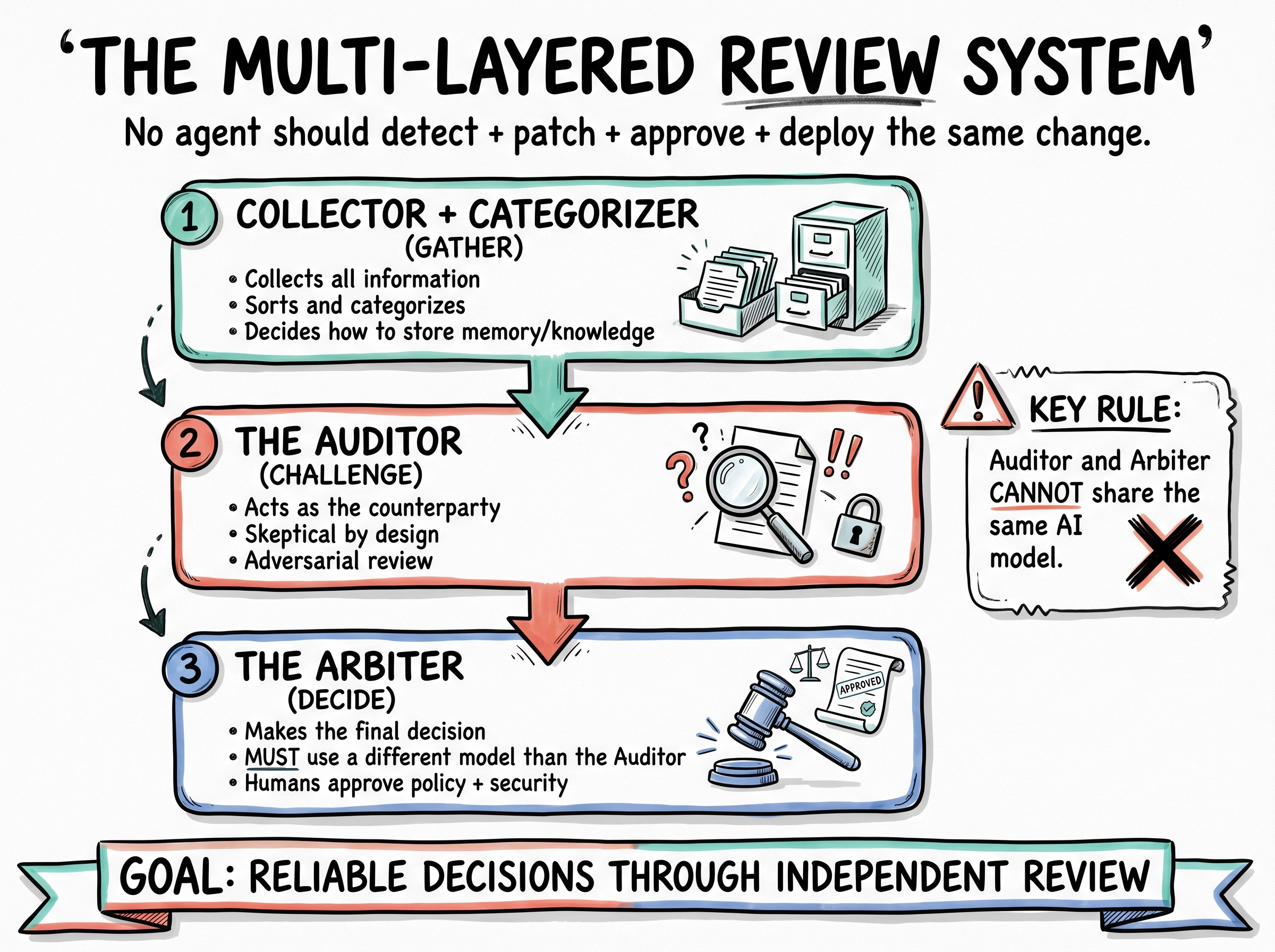
In our build, this takes the shape of three roles:
The Collector and Categorizer gathers information and decides how memory and knowledge should be structured.
The Auditor acts as the counterparty. Skeptical by design, adversarial by mandate.
The Arbiter makes the final call.
There is one rule I treat as non-negotiable: the Auditor and the Arbiter cannot share the same model. If one runs on ChatGPT 5.5, the other has to run on something else, say 4.7. The research is consistent on this point. LLMs tend to defend their own outputs, so reviews from the same model collapse into agreement. Different models, or even a context-free agent reviewing the work cold, surface the disagreements you actually need to see. I have been using Codex as that outside reviewer, since Claude Code does not allow the Claude plugin inside Codex. The loops compound well once the success criteria are set.
Codex described the same idea as an operating architecture:
“Workers do the business tasks. Local watchdogs run deterministic checks for each worker’s heartbeat, output freshness, queue depth, error rate, and last-good run. Department supervisors handle infra recovery, code repair, and cross-fleet visibility separately. A learning layer reads redacted outcomes and proposes updates by PR only. The key rule: no agent should both detect, patch, approve, and deploy the same change.” — Codex
That last line is the one I keep coming back to. No single agent should both detect, patch, approve, and deploy the same change. It is the AI equivalent of segregation of duties in finance, and for the same reason.
Codex extended the metaphor in a way I found useful:
“You want four kinds of staff: alarms that notice smoke fast, janitors that can do a few safe fixes automatically, engineers that can investigate and propose repairs, and librarians that learn from incidents and update the playbook. The mistake would be letting one person both notice smoke, rewrite the fire code, approve the change, and restart the building.” — Codex
Self-healing without separation of roles is not safety. It is one agent rewriting the fire code on its way out of the building.
The Ideal State Comes Before the How
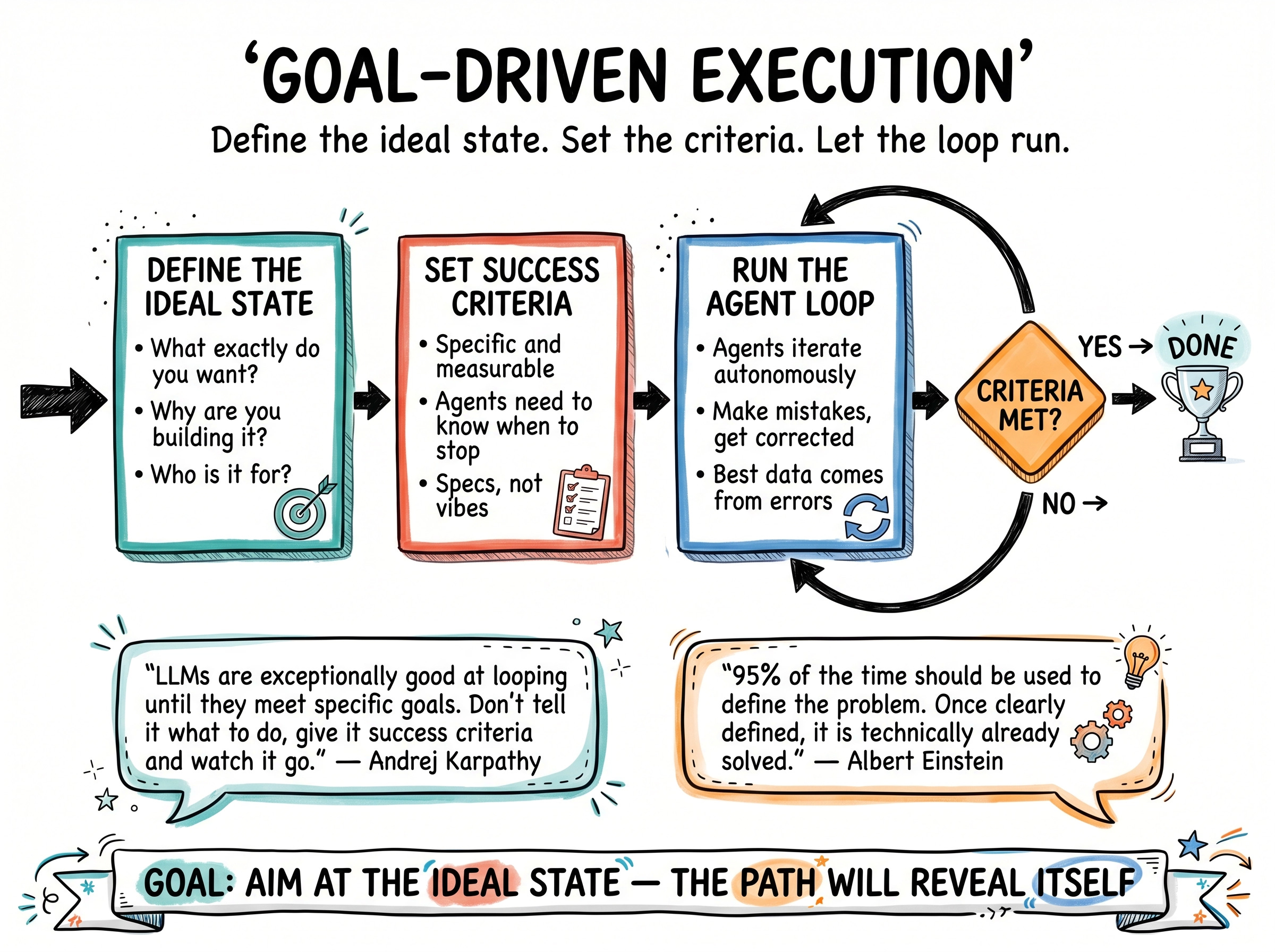
The third lesson came from finally installing the Karpathy skills repo I had saved for months. The reframe is simple. You need an ideal state before you write a single line of how.
What exactly do you want to achieve? What are the specs? Building the how has become cheap. The what is the hard part now. What are you building, why are you building it, and who is it for?
Once the ideal state is defined, the loop almost runs itself. Agents know what success looks like, they know when to stop, and they keep iterating until the criteria are met. The architecture I described above is the engine. The ideal state is the destination it drives toward.
The Best Data Comes From Mistakes
There is a thread that ties the technical and the human together, and it surfaced for me in a documentary by Zhang Xiaojun about Chen Xie for robots. His observation was that the highest-value training data is not data captured cleanly on the first try. The highest-value data is the data where the robot makes a mistake first, and the human corrects it. The error and the correction are the lesson.
That is also how a self-evolving system works. Self-awareness creates the record. Self-repair handles the trivial. Self-learning surfaces the patterns inside the mistakes. Self-evolving redesigns around what the mistakes revealed. Errors are not exceptions to the system. They are the curriculum.
As Einstein beautifully put: 95 percent of the time should go to defining the problem. Once the problem is clearly defined, it is technically already solved. I think the same logic applies to building agents. Almost all the difficulty lives in defining the ideal state. Everything after that is iteration.
The Question Worth Sitting With
So the question I would leave you with is the one I am sitting with myself.
What is the ideal state for your agents? What are you actually trying to build, and for whom? And while you are at it, what is the ideal state for you? Professionally, personally, the version of yourself you would recognize as having arrived.
Most of us cannot answer cleanly. That is fine. The point is not to have the answer before you start. The point is that once you aim at the ideal state, even imperfectly, the path begins to reveal itself.
Till then, cheers!
Previous column articles can be found here: