
Multi-Agent AI Coding Workflows
How I Ship Better Products Faster


Since the Codex plugin (Codex skill) was added to Claude Code, my development workflow has completely transformed. It feels like a genuine game changer. Recent research and developer experiences have increasingly highlighted a critical limitation in AI-assisted coding: a single model struggles to effectively review its own work. To achieve high-quality output, we need a multi-agent approach where different models review each other’s code.
Today, I want to share the strategies I use to make code review and product shipping more effective, efficient, and ultimately, to build better products.

Diagram 1: A multi-agent review process catches blind spots that a single model reviewing its own work typically misses.
Strategy 1: Codex as a Mandatory Code Reviewer
The first skill I want to highlight is the /codex plugin. It has been exceptionally helpful for conducting rigorous, adversarial code reviews.

To make this workflow effective, you can explicitly instruct Claude Code on your expectations. I tell it:
“Every change and every commit must be reviewed by Codex and must pass its checks. If Codex finds a bug, you must fix it and get it tested again until Codex says it is good to go. Only then can you move on to the next task.”
This approach has been working incredibly well. It is a joy to watch the system go through six rounds of automated Codex review, refining the code until it is perfect. One major advantage of this setup is context window efficiency. Because Codex uses its own context window for the review process, it does not consume the context limits of your active Claude Code session.

Diagram 2: The automated loop where Codex acts as a gatekeeper for every commit made by Claude Code.
Strategy 2: The Octopus Framework for Multi-Model Debate
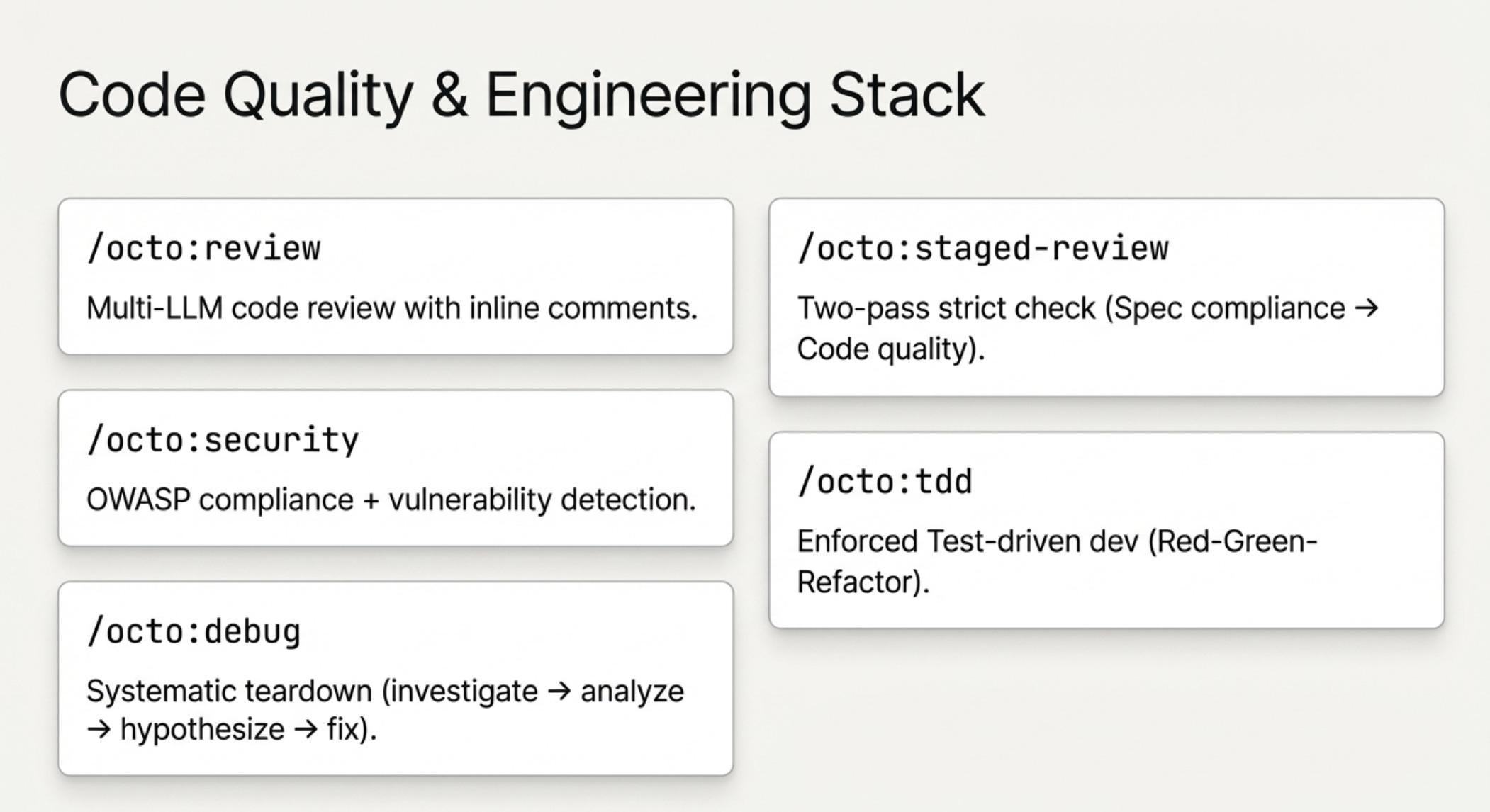
If you want an even more thorough review using different models, I recommend an open-source framework called Octopus. This tool allows you to plug in up to six different models simultaneously—including Qwen, Codex, and others.
You can configure these models to debate ideas, giving you diverse perspectives on architectural decisions. I find it particularly useful for having multiple models screen code to find bugs, as different models excel at identifying different types of issues.

Diagram 3: The Octopus framework orchestrates multiple models to debate ideas and aggregate bug findings.
However, I have not been using Octopus as frequently lately due to two main drawbacks:
1.Lack of Visibility: While you know the models are working, everything happens in the background. If you use VS Code or Claude Code, you cannot easily see how they debug or debate. To view their interactions, you have to use Tmux, which is not very straightforward to set up.
2.Redundancy: When using multiple powerful models (like GPT-4.1), they do a great job at debugging, but they often report the same bugs redundantly. Sometimes, less is more.
Strategy 3: The Meta-Review Prompting Technique
Whether I am coding, generalizing ideas, or planning a project, I often use a “meta-approach” to prompting.
I tell the Claude/any other Chat bot:
“Assume the work you just completed was done by a super junior developer. You are a senior manager or principal engineer with years of experience. You are auditing their work. Look for loopholes in the concepts, bugs in the features, and missing elements from a security or product perspective. Do a thorough audit: find the issues, identify the root causes, and propose solutions.”
You would be surprised by how many new issues this prompt uncovers. Sometimes, the model will completely change its initial approach based on this self-critique.
Pre-Planning for Token Efficiency
Another excellent strategy for saving tokens in your Claude Code sessions is two-phase pre-planning. You can draft your initial plan using Perplexity (or another model) and have it critique the plan several times. Usually, after two rounds of critique and debugging, the plan is robust. Only then do you bring the finalized plan into Claude Code to start executing.

Diagram 4: Using a lower-cost model for pre-planning saves tokens before executing the final plan in Claude Code.
The Human Element: Should We Still Read Code?
With all these automated reviews, a common question arises: Is it still necessary for us to read the code?
I have seen many posts on X (Twitter) claiming that nobody reads code anymore. While I agree that setting up a multi-agent framework makes code cleaner and easier to read, human oversight is still crucial. Catching issues early, before the codebase becomes too complicated, saves massive amounts of time.
For example, we know that Claude Code tends to over-engineer solutions. During one session, I was reading through the framework the AI had set up and caught a hard-coded value that needed to be flexible. Catching that manually saved hours of unnecessary debugging later.
However, I must admit that I have become the bottleneck in my own workflow. Watching Claude Code work and reading through everything it does means I cannot multitask. If you run multiple sessions simultaneously, the context switching becomes overwhelming. Ultimately, you have to balance speed with oversight, keeping in mind that the end goal is a product that works and performs well.

Diagram 5: The human developer remains essential for spot-checking and catching architectural flaws like hard-coded values.
Codex vs. Claude Code: Two Different Personalities
As I have played around with Codex and Claude Code, I have noticed distinct differences in their “personalities.”
Codex is incredibly straightforward. It gets right to the point and summarizes exactly what I want without needing to be asked twice about the implications of a change. Claude Code, on the other hand, provides a lot of “emotional support,” frequently telling me, “Okay, this idea is great!”
Codex is definitely less emotional and more clinical. Now that Codex has released its $100 plan, which I have been waiting for, I am excited to explore it further. Ultimately, it is not about choosing one over the other; the best approach is to combine their strengths.
Looking Ahead
I have also been exploring open-source and alternative models like Gemini 3 Pro, MiniMax 2.7, and Z.ai’s GLM5.1. While I will keep experimenting with them, Opus 4.6 remains unbeatable for now.
With the recent advancements from Codex, I am hopeful that open-source and proprietary models will soon be able to build powerful, multi-agent harnesses similar to what Claude Code has achieved. The future of coding tools is incredibly exciting, and I will definitely keep you all posted on my findings.
Till then, cheers!
Previous column articles can be found here: