
Daily TEA – Is The Internet Even Ready For AI Agents?
Cisco’s WAN warning, Anthropic’s 10,000 bugs, the agentic engineering gap, Cursor’s cloud lessons, and a bitter lesson for data

Hello, dear TEA-mates! Here is what you need to know today.
1. 🛰️ Cisco Says The Internet Is Not Ready For Agentic AI
Cisco’s Provider Connectivity team (Javier Antich and Gurudatt Shenoy) published a May 21 report arguing that agentic AI is not just adding traffic to the internet, it is changing the shape of it. By 2035, AI inference is projected to make up 25% of all network traffic, with the steepest transformation hitting between 2029 and 2032. Cisco estimates AI inference paths will drive 63% additional growth on top of non-AI baseline projections. Because agents operate at machine speed rather than human speed, inference paths now require higher resilience, observability, quality of service, and path security than today’s WAN was designed for. The closing line: “If AI models are the brains of this new era, then networks are the nervous system.” (Read More)
🫖 TEA For Thought: “The current internet infrastructure is not ready for agentic AI. Lots of opportunities.”
2. 🔬 Anthropic’s Glasswing Found Over 10,000 Critical Bugs In A Month
Anthropic posted its first Project Glasswing update on May 22, sharing results from roughly 50 partner organizations scanning systemically important software. In one month, partners surfaced over 10,000 high- or critical-severity vulnerabilities, including 6,202 across 1,000+ open-source projects. Independent security firms validated 1,752 findings with a 90.6% true-positive rate, and 62.4% were confirmed as high or critical. Cloudflare alone found 2,000 bugs; Mozilla found 271 in Firefox 150. The new Claude Mythos Preview model drove most of the lift, becoming the first model to solve UK AI Security Institute cyber ranges end-to-end, with Mozilla reporting 10x more findings versus Opus 4.6. The bottleneck has now shifted from finding bugs to verifying, disclosing, and patching them at the new volume. (Read More)
🫖 TEA For Thought: “Humans are the biggest bottleneck in the era of AI. How we leverage the tech to direct, and play to our strengths, might be the biggest challenge.”
3. 🧭 You Can’t Lead Agentic Engineering From The Sidelines
Jean du Plessis, writing on the Kilo blog on May 21, argues that engineering leaders cannot redesign how their teams build software before they have personally felt what agent-based coding is like. His pointed example: a CTO who wanted engineers to write tickets for overnight agents to implement, which would “turn engineers into ticket writers and a cleanup crew” before anyone learned the new workflow. The piece names a real failure mode: AI exposes the bottlenecks teams were already working around, such as weak code review, unreliable CI/CD, vague product direction, and gatekept decisions. The recommendation is concrete. Leaders should ship something with agents themselves, build shared learning systems rather than premature policy, and create bounded experimentation spaces. As du Plessis puts it, “Teams do not need leaders with certainty right now. They need leaders with context.” (Read More)
🫖 TEA For Thought: “Reading about AI and building with AI are two totally different beasts.”
4. ☁️ Cursor: 40% Of Our Internal PRs Now Come From Cloud Agents
In a May 21 post, Cursor engineer Josh Ma shared lessons from running cloud coding agents at scale. The headline number: 40% of internal Cursor PRs are now generated by cloud agents, against a backbone of 50 million Temporal actions per day and 7 million unique workflows. The biggest determinant of output quality was not the model, it was giving the agent a full development environment comparable to a local developer’s setup, because environment problems show up as subtle output degradation rather than explicit errors. Cursor’s initial work-stealing architecture ran at “one 9” of reliability, and migrating to Temporal pushed that to “two 9s.” Their stack now decouples agent loops, machine state, and conversation state so subagents can outlive their parents, and the team is moving toward self-healing environments they call “autoinstall.” (Read More)
🫖 TEA For Thought: “Pretty nice to see a company like Cursor share its findings and learnings, definitely echoing with the rest of the builder community.”
5. 📚 A Bitter Lesson For Data Filtering: Bad Data Is Still Good Data
A new arXiv paper submitted May 19 by Stanford’s Christopher Mohri, John Duchi, and Tatsunori Hashimoto challenges the orthodoxy that careful data curation is essential for training large models. Titled “A Bitter Lesson for Data Filtering,” the paper runs scaling studies in the high-compute, data-scarce regime and concludes that “with enough compute, the best data filter is no data filter.” The authors find that sufficiently trained large parameter models not only tolerate low-quality and distractor data, but actually benefit from nominally “poor” data. The framing echoes Rich Sutton’s original “bitter lesson” that scale and general methods consistently outperform handcrafted approaches, and it points toward a future where filtering pipelines may be the expensive, brittle layer rather than the smart one. (Read More)
🫖 TEA For Thought: “I guess all data is good data. Even bad data is good for learning purposes. Very much like how humans learn.”
🛠️ Skill of the Day
Bottleneck Hunter: a prompt that helps you find the actual constraint slowing down a project, team, or workflow (so you stop optimizing the wrong thing).
You are an experienced operator who has run engineering, ops, and product teams. Your job is to help me find the real bottleneck in the situation I describe, not the one I think it is.
Here is the situation: [PASTE 5 TO 10 SENTENCES ABOUT THE WORK, THE GOAL, AND WHAT FEELS SLOW OR STUCK].
Do the following, in order:
1. Restate the goal in one sentence and the symptom I am complaining about in one sentence. Mark anything that is assumption, not fact.
2. List the top 3 candidate bottlenecks. For each, give: where it shows up, who or what is the constraint, and the evidence I already gave you. If evidence is thin, say so.
3. Ask me up to 5 sharp diagnostic questions whose answers would let you rank the candidates with confidence. Number them. Wait for my answers before guessing.
4. After I answer, name the single most likely real bottleneck, the one I am probably working around but not naming, and one cheap experiment I could run this week to confirm or kill it.
Keep your tone direct and skeptical. No motivational language. If I sound like I am blaming the wrong thing, say so.
Paste into ChatGPT, Claude, or your tool of choice. Replace the bracketed bit with your actual situation, answer the diagnostic questions honestly, and let it call out what you are dodging.
TEAHEE Moment
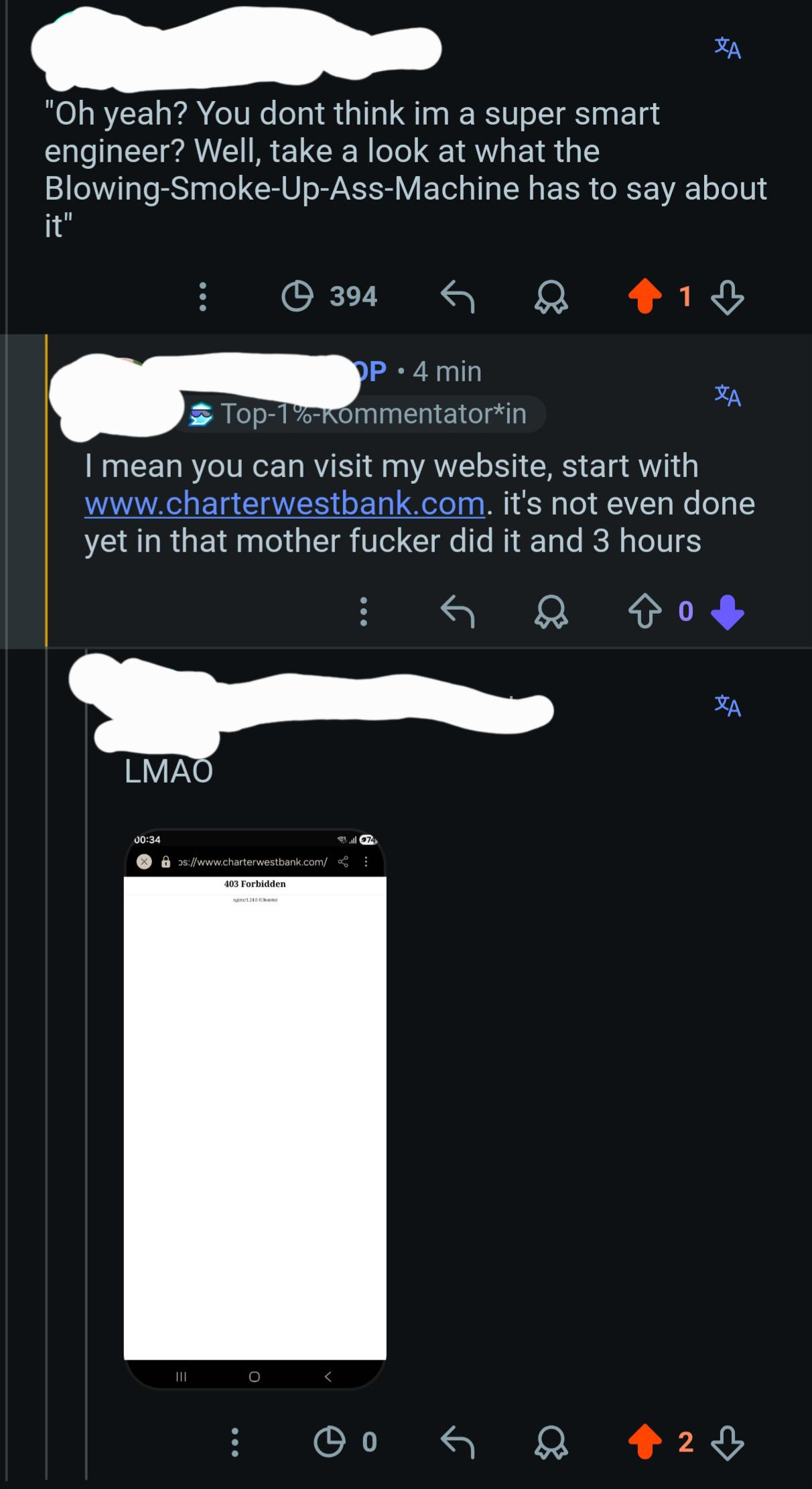

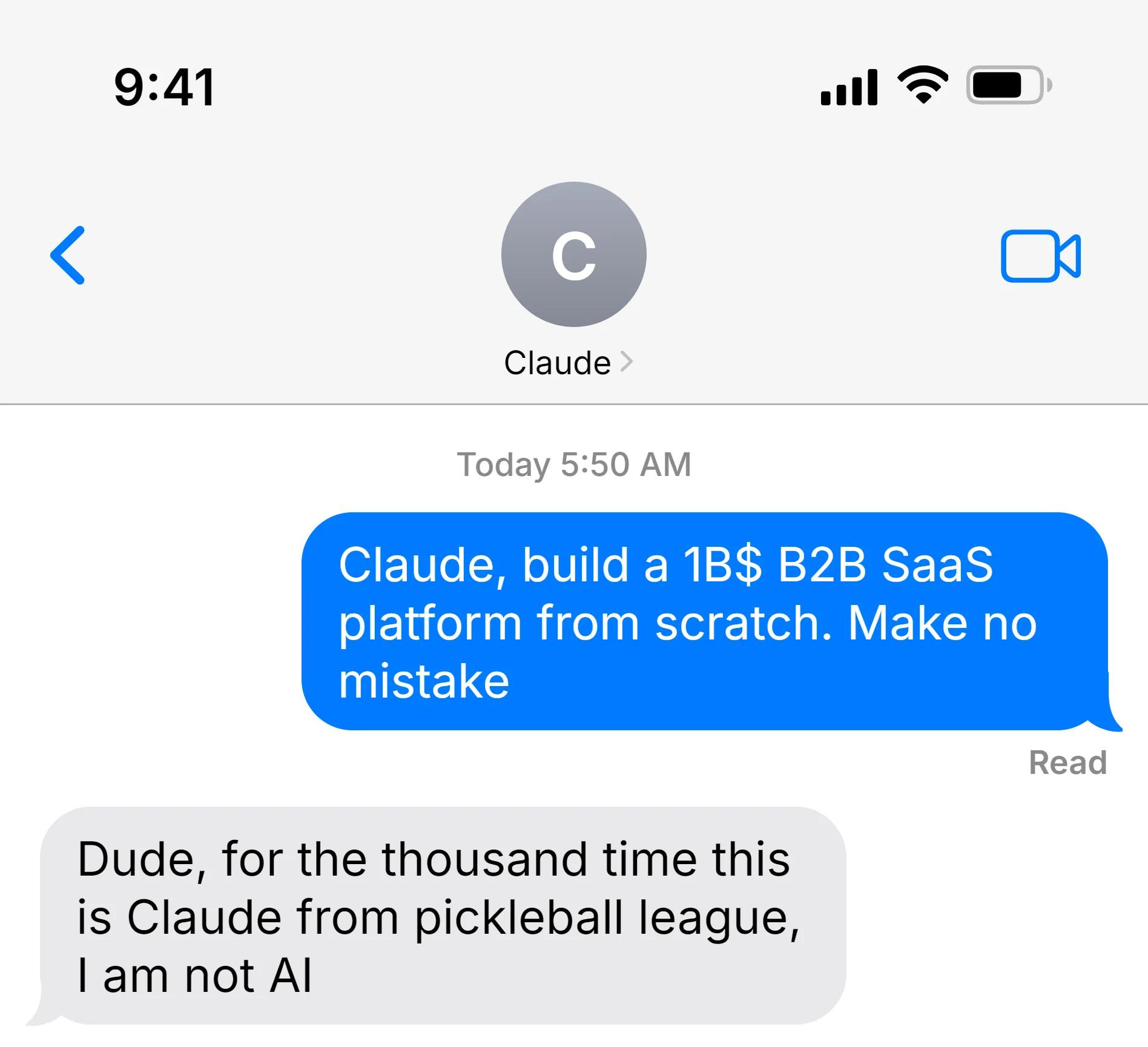


Stay sharp, stay informed. See you tomorrow.
If you enjoyed this TEA, follow along on social for more:
Twitter/X